了解如何生成或操作文本
原文链接:Text completion – OpenAI API
介绍
完成端点可用于各种任务。它为我们的任何模型提供了一个简单但功能强大的界面。您输入一些文本作为提示,模型将生成一个文本补全,尝试匹配您为其提供的任何上下文或模式。例如,如果你给 API 提示,“As Descartes said, I think, therefore”,它将以很高的概率返回完成“I am”。
开始探索完井的最佳方式是通过我们的游乐场。它只是一个文本框,您可以在其中提交提示以生成完成。要亲自尝试,请在 Playground 中打开此示例:
Write a tagline for an ice cream shop.
提交后,您将看到如下所示的内容:
Write a tagline for an ice cream shop.
We serve up smiles with every scoop!
您看到的实际完成情况可能会有所不同,因为默认情况下 API 是不确定的。这意味着每次调用它时,即使提示保持不变,您也可能得到略有不同的完成。将temperature设置为 0 将使输出大部分具有确定性,但可能会保留少量可变性。
这个简单的文本输入、文本输出界面意味着您可以通过提供说明或仅提供您希望它做什么的几个示例来“编程”模型。它的成功通常取决于任务的复杂性和提示的质量。一个好的经验法则是考虑如何写一个单词问题供中学生解决。编写良好的提示为模型提供了足够的信息,以便了解您想要什么以及它应该如何响应。
本指南涵盖一般提示设计最佳实践和示例。要了解有关使用我们的 Codex 模型处理代码的更多信息,请访问我们的代码指南。
请记住,默认模型的训练数据在 2021 年中断,因此它们可能不了解当前事件。我们计划在未来增加更多的持续培训。
提示设计
基本
我们的模型可以做任何事情,从生成原始故事到执行复杂的文本分析。因为他们可以做很多事情,所以你必须明确描述你想要什么。展示,而不仅仅是讲述,通常是良好提示的秘诀。
创建提示有三个基本准则:
展示和讲述。通过说明、示例或两者的组合来明确您想要什么。如果希望模型按字母顺序对项目列表进行排名或按情绪对段落进行分类,请显示这是您想要的。
提供高质量的数据。如果尝试生成分类器或让模型遵循模式,请确保有足够的示例。一定要校对你的例子——这个模型通常足够聪明,可以看穿基本的拼写错误并给你一个响应,但它也可能认为这是故意的,它可能会影响响应。
检查您的设置。温度和top_p设置控制模型在生成响应时的确定性。如果你要求它给出只有一个正确答案的答案,那么你需要把这些设置得更低。如果您正在寻找更多样化的响应,那么您可能希望将它们设置得更高。人们使用这些设置的第一个错误是假设它们是“聪明”或“创造力”控件。
故障 排除
如果在使 API 按预期执行时遇到问题,请按照以下清单操作:
- 是否清楚预期的一代应该是什么?
- 有足够的例子吗?
- 您是否检查过您的示例是否有错误?(API 不会直接告诉你)
- 是否正确使用温度和top_p?
分类
为了使用 API 创建文本分类器,我们提供了任务的描述和一些示例。在此示例中,我们展示了如何对推文的情绪进行分类。
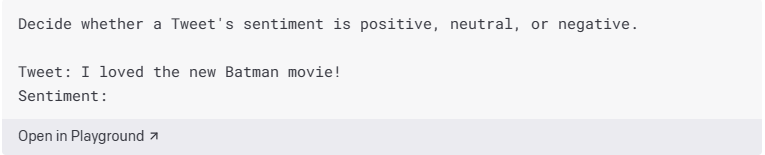
在这个例子中,值得关注的几个功能:
- 使用简单的语言来描述您的输入和输出。我们使用简单的语言输入“推文”和预期的输出“情绪”。最佳做法是,从简单的语言描述开始。虽然您通常可以使用速记或键来指示输入和输出,但最好从尽可能具有描述性开始,然后向后工作以删除多余的单词,看看性能是否保持一致。
- 向 API 展示如何响应任何案例。在此示例中,我们在指令中包含可能的情绪标签。中性标签很重要,因为在许多情况下,即使是人类也很难确定某事是积极的还是消极的,而在这种情况下,它两者都不是。
- 对于熟悉的任务,您需要更少的示例。对于此分类器,我们不提供任何示例。这是因为 API 已经了解了情绪和推文的概念。如果要为 API 可能不熟悉的内容构建分类器,则可能需要提供更多示例。
提高分类器的效率
现在我们已经掌握了如何构建分类器,让我们以这个例子为例,使其更加高效,以便我们可以使用它从一个 API 调用中获取多个结果。
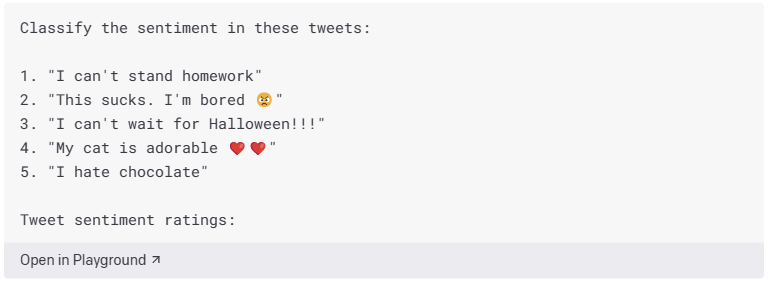
我们提供了一个带编号的推文列表,因此 API 可以在一次 API 调用中对五条(甚至更多)推文进行评级。
请务必注意,当您要求 API 创建列表或评估文本时,您需要特别注意概率设置(Top P 或温度)以避免漂移。
- 确保通过运行多个测试正确校准概率设置。
- 不要让你的列表太长,否则 API 可能会漂移。
生成
使用 API 可以完成的最强大但最简单的任务之一是生成新的想法或输入版本。你可以要求任何东西,从故事创意到商业计划,到角色描述和营销口号。在此示例中,我们将使用 API 创建在健身中使用虚拟现实的想法。

如果需要,您可以通过在提示中包含一些示例来提高响应的质量。
谈话
该 API 非常擅长与人类甚至自身进行对话。只需几行指令,我们就看到 API 可以作为客户服务聊天机器人执行,它可以智能地回答问题而不会感到慌乱,或者是一个明智的对话伙伴,可以开玩笑和双关语。关键是告诉 API 它应该如何运行,然后提供一些示例。
下面是 API 扮演 AI 回答问题的角色的示例:
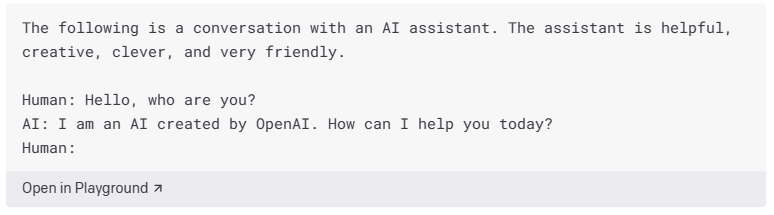
这就是创建一个能够进行对话的聊天机器人所需要的一切。在它的简单性之下,有几件事值得关注:
- 我们告诉 API 意图,但我们也告诉它如何行为。就像其他提示一样,我们将 API 提示到示例所代表的内容,但我们还添加了另一个关键细节:我们向它提供了有关如何与短语“助手乐于助人、富有创造力、聪明且非常友好”进行交互的明确说明。如果没有该指令,API 可能会偏离并模仿与之交互的人,并变得讽刺或我们想要避免的其他行为。
- 我们给 API 一个标识。一开始,我们让 API 作为 AI 助手进行响应。虽然 API 没有固有标识,但这有助于它以尽可能接近事实的方式进行响应。您可以通过其他方式使用身份来创建其他类型的聊天机器人。如果你告诉API作为一个在生物学领域担任研究科学家的女性做出回应,你会从API得到聪明而深思熟虑的评论,类似于你对具有这种背景的人的期望。
在这个例子中,我们创建了一个有点讽刺的聊天机器人,它不情愿地回答问题:

为了创建一个有趣且有点有用的聊天机器人,我们提供了一些问题和答案示例,展示了 API 如何回复。只需要几个讽刺的响应,API 就能够拾取模式并提供无穷无尽的尖刻响应。
转型
API 是一种语言模型,它熟悉单词和字符可用于表达信息的各种方式。范围从自然语言文本到代码和英语以外的语言。API 还能够在允许它以不同方式总结、转换和表达内容的级别上理解内容。
翻译
在此示例中,我们向 API 展示了如何将英语转换为法语、西班牙语和日语:

此示例之所以有效,是因为 API 已经掌握了这些语言,因此无需尝试教授它们。
如果你想从英语翻译成API不熟悉的语言,你需要为它提供更多的例子,甚至微调一个模型来流利地做到这一点。
转换
在此示例中,我们将电影名称转换为表情符号。这显示了 API 对拾取模式和处理其他字符的适应性。

综述
API 能够掌握文本的上下文并以不同的方式改写它。在这个例子中,我们创建了一个解释,一个孩子可以从更长、更复杂的文本段落中理解。这说明 API 对语言有深入的掌握。

完成
虽然所有提示都会导致完成,但在您希望 API 从上次中断的地方继续的情况下,将文本完成视为自己的任务可能会很有帮助。例如,如果给出此提示,API 将继续思考垂直农业。您可以降低温度设置以使 API 更专注于提示的意图,也可以提高温度设置以使其偏离正切线。

下一个提示显示了如何使用完成来帮助编写 React 组件。我们向 API 发送一些代码,它能够继续其余的代码,因为它了解 React 库。我们建议将我们的 Codex 模型用于涉及理解或生成代码的任务。要了解更多信息,请访问我们的代码指南。

事实答复
API 有很多知识,它是从训练它的数据中学习的。它还能够提供听起来非常真实但实际上是编造的响应。有两种方法可以限制 API 组成答案的可能性。
- 为 API 提供基本事实。如果您向 API 提供文本正文来回答有关(如维基百科条目)的问题,则不太可能虚构响应。
- 使用低概率并向 API 展示如何说“我不知道”。如果 API 明白,在不太确定响应的情况下,说“我不知道”或某些变体是合适的,那么它就不太倾向于编造答案。
在此示例中,我们向 API 提供它知道的问题和答案的示例,然后提供它不知道的事情的示例并提供问号。我们还将概率设置为零,以便 API 更有可能在有任何疑问时响应“?”。

插入文本试用版
完成终结点还支持通过在前缀提示之外提供后缀提示来在文本中插入文本。在编写长篇文本、段落之间过渡、遵循大纲或引导模型走向结尾时,自然会出现这种需求。这也适用于代码,可用于插入函数或文件的中间。请访问我们的代码指南以了解更多信息。
为了说明后缀上下文对我们的预测能力有多重要,请考虑提示,“今天我决定做出重大改变。人们可以通过多种方式想象完成句子。但是,如果我们现在提供故事的结局:“我的新头发得到了很多赞美!”,预期的完成就变得清晰了。

通过为模型提供额外的上下文,它可以更具可操纵性。但是,对于模型来说,这是一项更具限制和挑战性的任务。
最佳实践
插入文本是测试版中的一项新功能,您可能需要修改使用 API 的方式以获得更好的结果。以下是一些最佳做法:
使用 max_tokens > 256。该模型更擅长插入较长的完成项。如果max_tokens太小,模型可能会在连接到后缀之前被切断。请注意,即使使用较大的max_tokens,也只需为生成的代币数量付费。
更喜欢finish_reason==“停止”。当模型到达自然停止点或用户提供的停止序列时,它将finish_reason设置为“停止”。这表明模型已成功连接到后缀,并且是完成质量的良好信号。这对于在使用 n > 1 或重新采样时在几个完成之间进行选择尤其重要(请参阅下一点)。
重新采样 3-5 次。虽然几乎所有完成都连接到前缀,但在更困难的情况下,模型可能难以连接后缀。我们发现,在这种情况下,重新采样 3 或 5 次(或使用 k=3,5 的 best_of)并选择以“停止”作为其finish_reason的样本可能是一种有效的方法。在重新采样时,您通常需要更高的温度来增加多样性。
注意:如果所有返回的示例都有 finish_reason == “length”,则可能是max_tokens太小并且模型在设法自然连接提示和后缀之前耗尽了令牌。考虑在重新采样前增加max_tokens。
尝试提供更多线索。在某些情况下,为了更好地帮助模型的生成,您可以通过提供一些模型可以遵循的模式示例来提供线索,以决定停止的自然位置。

编辑文本 Alpha
编辑端点可用于编辑文本,而不仅仅是完成文本。您提供一些文本和有关如何修改它的说明,模型将尝试相应地对其进行编辑。这是用于翻译、编辑和调整文本的自然界面。这对于重构和使用代码也很有用。请访问我们的代码指南以了解更多信息。在此初始测试期内,编辑端点的使用是免费的。text-davinci-edit-001
例子
