马舒明 王宏宇1马玲玲 王磊 王文辉
黄少涵 李东瑞平 王继龙 薛富茹 魏彦⋄
https://aka.ms/GeneralAI
同等贡献。⋄通讯作者。S. 马、L. 马、L. Wang、W. Wang、S. Huang、L. Dong、J. Xue、F. Wei 就职于 Microsoft Research。H. Wang 和 R. Wang 就职于中国科学院大学。
0. 摘要
最近的研究,如BitNet[23],正在为 1 位大型语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1 位 LLM 变体,即 BitNet b1.58,其中 LLM 的每个参数(或权重)都是三元 {-1, 0, 1}。它与全精度(即 FP16 或 BF16)Transformer LLM 在困惑度和最终任务性能方面具有相同的模型大小和训练令牌相匹配,同时在延迟、内存、吞吐量和能耗方面更具成本效益。 更深刻的是,1.58 位 LLM 定义了一种新的扩展定律和方法,用于训练高性能和具有成本效益的新一代 LLM。此外,它还实现了一种新的计算范式,并为设计针对 1 位 LLM 优化的特定硬件打开了大门。
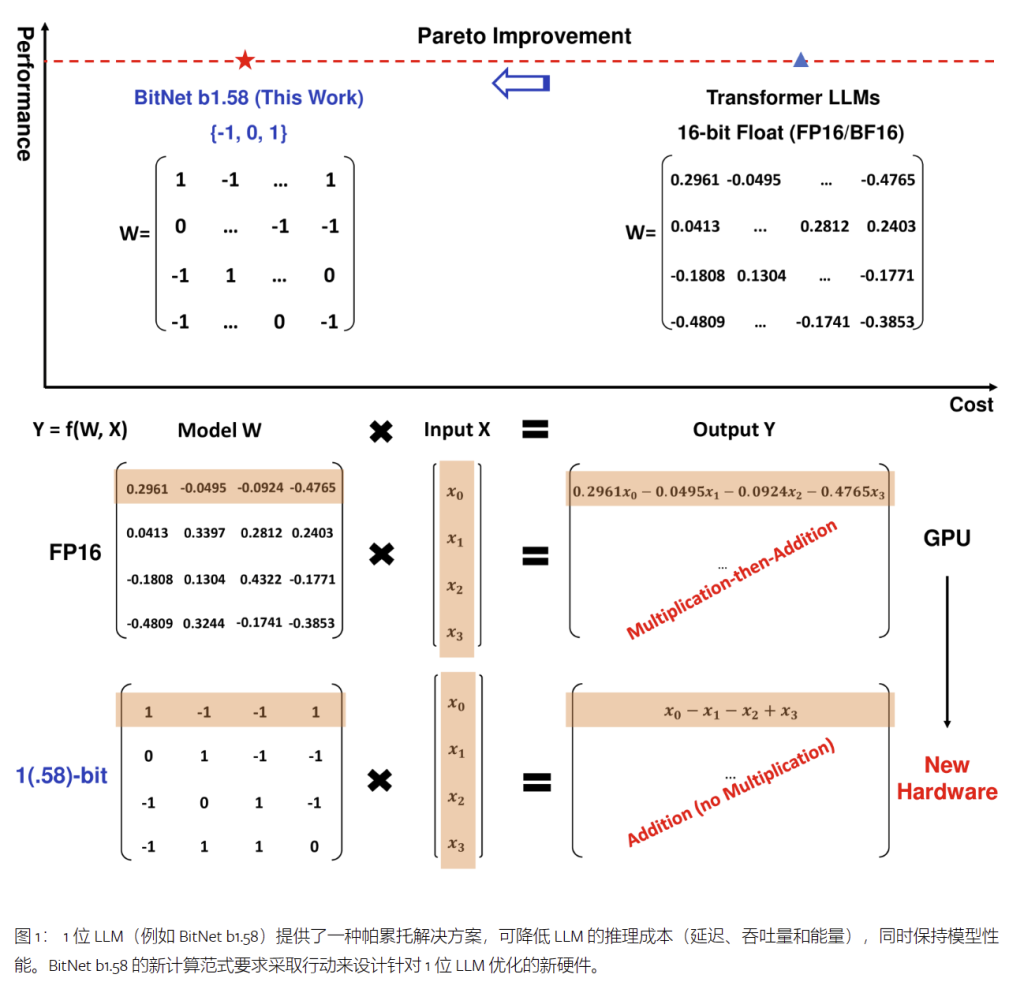
1. 1 位 LLM 时代(The Era of 1-bit LLMs)
近年来,人工智能领域的大型语言模型 (LLM) 的规模和功能迅速增长。这些模型在广泛的自然语言处理任务中表现出了卓越的性能,但它们不断扩大的规模给部署带来了挑战,并引发了人们对高能耗对环境和经济影响的担忧。 解决这些挑战的一种方法是使用训练后量化来创建用于推理的低位模型[24,5,2,18].这种技术降低了权重和激活的精度,大大降低了 LLM 的内存和计算要求。趋势是从 16 位转向更低的位,例如 4 位变体[5,9].然而,训练后量化是次优的,尽管它被广泛用于工业 LLM。
最近关于 1 位模型架构(如 BitNet)的工作[23],为降低 LLM 的成本同时保持其性能提出了一个有前途的方向。Vanilla LLM 是 16 位浮点值(即 FP16 或 BF16),任何 LLM 的大部分都是矩阵乘法。因此,主要的计算成本来自浮点加法和乘法运算。相比之下,BitNet 的矩阵乘法仅涉及整数加法,这为 LLM 节省了数量级的能源成本。由于许多芯片计算性能的根本限制是功耗,因此节能也可以转化为更快的计算。
除了计算之外,在推理过程中,将模型参数从DRAM传输到片上加速器(例如SRAM)的存储器的过程可能非常昂贵。有人试图扩大SRAM以提高吞吐量,但这会带来比DRAM高得多的成本。与全精度模型相比,从容量和带宽的角度来看,1 位 LLM 的内存占用要低得多。这可以显著降低从 DRAM 加载权重的成本和时间,从而实现更快、更高效的推理。
在这项工作中,我们引入了一个重要的 1 位 LLM 变体,称为 BitNet b1.58,其中每个参数都是三元的,取值为 {-1, 0, 1}。我们在原来的 1 位 BitNet 中添加了一个额外的值 0,从而在二进制系统中产生 1.58 位。BitNet b1.58 保留了原始 1 位 BitNet 的所有优点,包括其新的计算范式,该范式几乎不需要矩阵乘法运算,并且可以高度优化。此外,与FP16 LLM基线相比,它具有与原始1位BitNet相同的能耗,并且在内存消耗,吞吐量和延迟方面效率更高。此外,BitNet b1.58 还具有两个额外的优势。首先,由于其对特征过滤的明确支持,其建模能力更强,通过在模型权重中包含 0 来实现,这可以显着提高 1 位 LLM 的性能。 其次,我们的实验表明,BitNet b1.58 在困惑度和最终任务性能方面都可以匹配全精度(即 FP16)基线, 从 3B 大小开始,当使用相同的配置(例如,模型大小、训练令牌等)时。
2. BitNet b1.58
BitNet b1.58 基于 BitNet 架构,它是一个取代 nn 的 Transformer。线性与 BitLinear。它是从头开始训练的,具有 1.58 位权重和 8 位激活。与原来的BitNet相比,它引入了一些修改,我们总结如下。
2.1 量化函数(Quantization Function)
为了将权重限制为 -1、0 或 +1,我们采用了 absmean 量化函数。它首先按其平均绝对值缩放权重矩阵,然后将每个值四舍五入到 {-1, 0, +1} 之间最接近的整数:
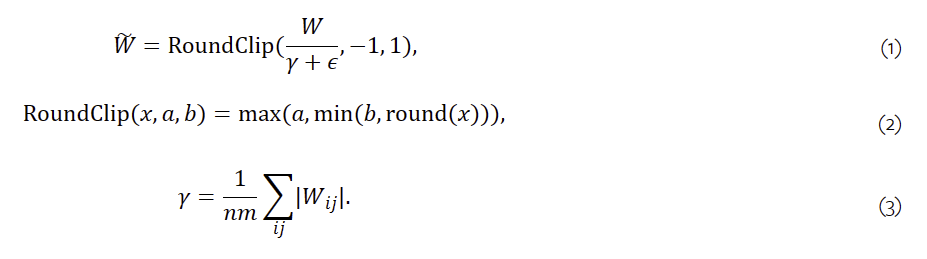
激活的量化函数遵循 BitNet 中的相同实现,只是我们不会将非线性函数之前的激活缩放到范围[0,Qb].相反,激活将全部缩放到[−Qb,Qb]每个令牌来摆脱零点量化。这对于实现和系统级优化来说都更加方便和简单,同时在我们的实验中对性能的影响可以忽略不计。
2.2 类似 LLaMA 的组件(LLaMA-alike Components)
LLaMA的架构[19,20]一直是开源 LLM 事实上的支柱。为了拥抱开源社区,我们的 BitNet b1.58 设计采用了类似 LLaMA 的组件。具体来说,它使用 RMSNorm[27]、斯威格卢(SwiGLU)[16]、旋转嵌入(rotary embedding)[14],并消除所有偏见。通过这种方式,BitNet b1.58 可以集成到流行的开源软件(例如,Huggingface、vLLM[8]和 llama.cpp1)以最小的努力。
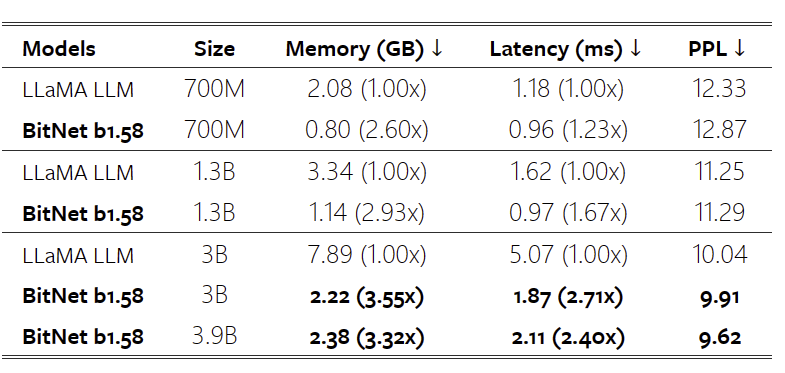
表 1:BitNet b1.58 和 LLaMA LLM 的困惑度以及成本。
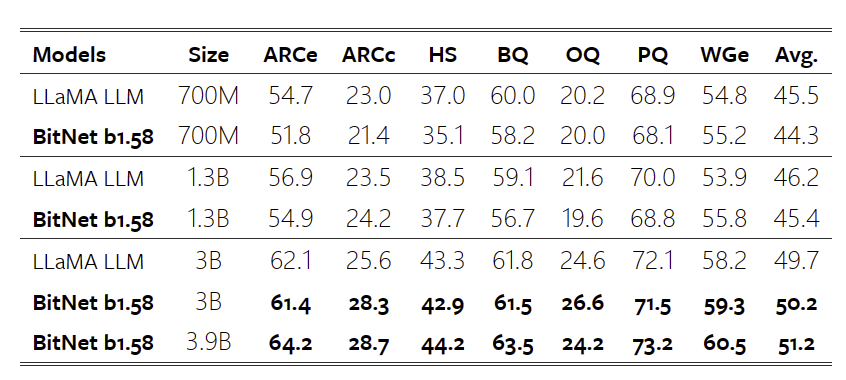
表2:BitNet b1.58 和 LLaMA LLM 在最终任务上的零点精度。
3. 结果(Results)
我们将 BitNet b1.58 与我们复制的各种尺寸的 FP16 LLaMA LLM 进行了比较。为了确保公平的比较,我们在 RedPajama 数据集上预训练了模型[4]1000亿个代币。我们评估了包括ARC-Easy在内的一系列语言任务的零样本性能[25]、ARC-Challenge[25], Hellaswag[26], Winogrande [15], PIQA [1], OpenbookQA [10], and BoolQ [3].我们还报告了WikiText2上的验证困惑[11]和 C4[13]数据。
我们比较了 LLaMA LLM 和 BitNet b1.58 的运行时 GPU 内存和延迟。使用FasterTransformer测量结果2代码库,针对 GPU 设备上的 LLM 推理延迟进行了优化。Ladder 的 2 位内核[22]还集成了 BitNet b1.58。我们报告了每个输出令牌的时间,因为它是推理的主要成本。
表 1 总结了 BitNet b1.58 和 LLaMA LLM 的困惑和成本。它表明,BitNet b1.58 在 3B 模型大小下开始与全精度 LLaMA LLM 相匹配,同时速度提高了 2.71 倍,使用的 GPU 内存减少了 3.55 倍。特别是,具有 3.9B 模型大小的 BitNet b1.58 速度快 2.4 倍,内存消耗减少 3.32 倍,但性能明显优于 LLaMA LLM 3B。
表 2 报告了最终任务的零点精度的详细结果。我们遵循了 lm-evaluation-harness 的管道3执行评估。结果表明,随着模型规模的增加,BitNet b1.58和LLaMA LLM之间的性能差距逐渐缩小。更重要的是,BitNet b1.58 可以匹配从 3B 大小开始的全精度基线的性能。与对困惑的观察类似,最终任务结果显示,BitNet b1.58 3.9B 以更低的内存和延迟成本优于 LLaMA LLM 3B。这表明 BitNet b1.58 是对最先进的 LLM 模型的帕累托改进。
3.1 内存和延迟(Memory and Latency)
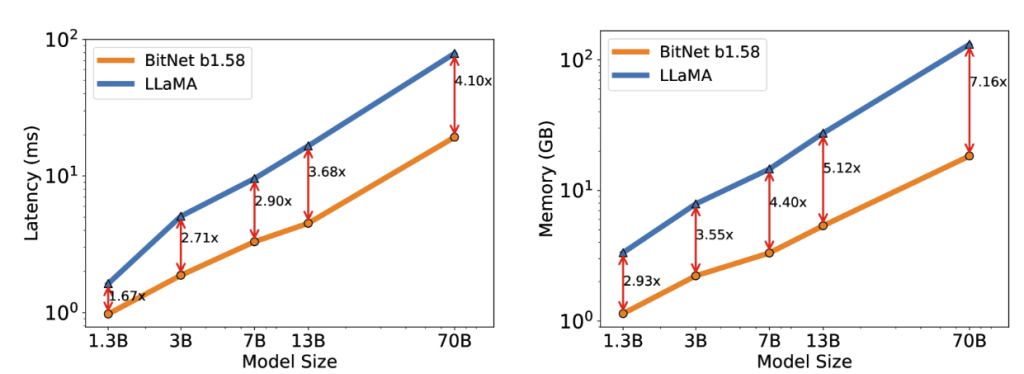
图 2:BitNet b1.58 解码延迟(左)和内存消耗(右)随模型大小的变化
我们进一步将模型尺寸扩大到 7B、13B 和 70B,并评估了成本。图 2 说明了延迟和内存的趋势,显示随着模型大小的扩展,加速也会增加。特别是,BitNet b1.58 70B 比 LLaMA LLM 基线快 4.1 倍。这是因为 nn.线性随着模型大小的增长而增长。内存消耗遵循类似的趋势,因为嵌入保持全精度,并且对于较大的型号,其内存比例较小。延迟和内存都是用 2 位内核测量的,因此仍有优化的空间以进一步降低成本。
3.2 能源(Energy)
我们还估计了 BitNet b1.58 和 LLaMA LLM 的算术运算能耗。 我们主要关注矩阵乘法的计算,因为它 对 LLM 成本的贡献最大。 图 3 说明了能源成本的构成。BitNet b1.58 的大部分是 INT8 加法计算,而 LLaMA LLM 由 FP16 加法和 FP16 乘法组成。根据能量模型[7,28],BitNet b1.58 为 7nm 芯片上的矩阵乘法节省了 71.4 倍的算术运算能耗。我们进一步报告了具有 512 个代币的模型的端到端能源成本。我们的结果表明,随着模型规模的扩大,与FP16 LLaMA LLM基线相比,BitNet b1.58在能耗方面的效率越来越高。这是因为 nn.线性随着模型大小的增长而增长,而对于较大的模型,其他组件的成本更小。
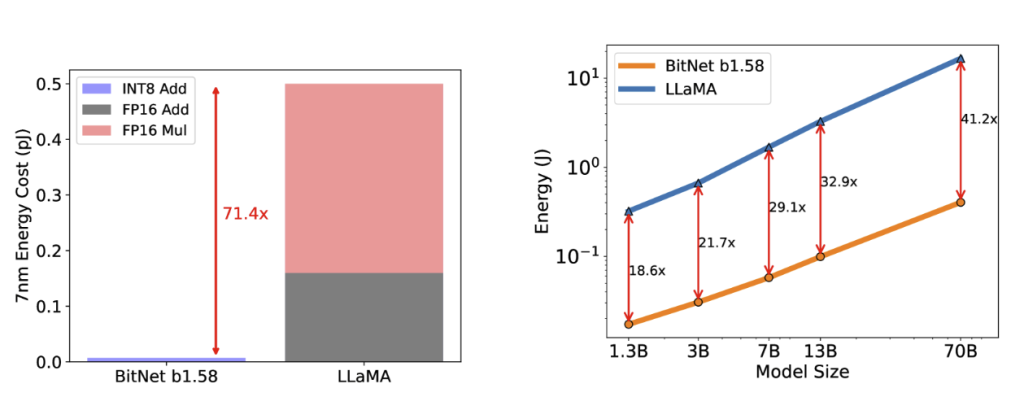
图 3:BitNet b1.58 与 LLaMA LLM 在 7nm 工艺节点上的能耗相比。左边是算术运算能量的分量。右边是不同型号尺寸的端到端能源成本
3.3 吞吐量(Throughput)

表3:BitNet b1.58 70B 和 LLaMA LLM 70B 之间的吞吐量比较
我们使用流水线并行性比较了 BitNet b1.58 和 LLaMA LLM 与两个 80GB A100 卡上 70B 参数的吞吐量[6]以便 LLaMA LLM 70B 可以在设备上运行。我们增加了批处理大小,直到达到 GPU 内存限制,序列长度为 512。表 3 显示,BitNet b1.58 70B 可以支持高达 11 倍的 LLaMA LLM 批量大小,从而将吞吐量提高 8.9 倍。
BitNet b1.58 在模型性能和推理成本方面实现了新的扩展定律。作为参考,我们可以根据图 2 和图 3 中的结果,在 1.58 位和 16 位的不同模型大小之间获得以下等价性。
- • 13B BitNet b1.58 在延迟、内存使用和能耗方面比 3B FP16 LLM 更有效。
- • 30B BitNet b1.58 在延迟、内存使用和能耗方面比 7B FP16 LLM 更有效。
- • 70B BitNet b1.58 在延迟、内存使用和能耗方面比 13B FP16 LLM 更有效。
3.4 使用2T代币进行训练
训练令牌的数量是 LLM 的一个关键因素。为了测试 BitNet b1.58 在代币方面的可扩展性,我们按照 StableLM-3B 的数据配方训练了一个带有 2T 代币的 BitNet b1.58 模型[17],这是最先进的开源 3B 模型。这两个模型都是在由 Winogrande 组成的基准测试上评估的[15]、PIQA [1], SciQ [21], LAMBADA [12]和 ARC-easy[25].我们在表4中报告了零点射击精度。对于以准确度和归一化准确度测量的任务,我们取两者的平均值。StableLM 3b 在 2T 代币上的结果直接取自其技术报告。我们的研究结果表明,BitNet b1.58 在所有终端任务上都取得了卓越的性能,表明 1.58 位 LLM 也具有很强的泛化能力。

表 4:BitNet b1.58 与 StableLM-3B 与 2T 代币的比较
4. 讨论和今后的工作
1 位混合专家 (MoE) LLM
专家混合 (MoE) 已被证明是 LLM 的一种具有成本效益的方法。虽然它显着降低了计算 FLOP,但高内存消耗和芯片间通信开销限制了其部署和应用。这些挑战可以通过 1.58 位 LLM 来解决。 首先,减少的内存占用减少了部署 MoE 模型所需的设备数量。此外,它还大大减少了跨网络传输激活的开销。最终,如果整个模型可以放在一个芯片上,就不会有开销。
LLM 中长序列的原生支持
在LLM时代,处理长序列的能力已成为关键需求。长序列推理的一个主要挑战是 KV 缓存引入的内存消耗。BitNet b1.58 代表了向长序列的原生支持迈出的重要一步,因为它将激活从 16 位减少到 8 位,允许在相同资源的情况下上下文长度增加一倍。 对于 1.58 位 LLM,这可以进一步无损压缩到 4 位甚至更低,我们将其留作未来的工作。
边缘和移动设备上的 LLM
使用 1.58 位 LLM 有可能大大提高边缘和移动设备上语言模型的性能。这些设备通常受到其内存和计算能力的限制,这可能会限制 LLM 的性能和规模。然而,1.58 位 LLM 的内存和能耗降低,允许它们部署在这些设备上,从而实现以前不可能实现的广泛应用。这可以大大增强边缘和移动设备的能力,并实现新的和令人兴奋的LLM应用。 此外,1.58 位 LLM 对 CPU 设备更友好,CPU 设备是边缘和移动设备中使用的主要处理器。这意味着BitNet b1.58可以在这些设备上高效执行,进一步提高其性能和功能。
用于 1 位 LLM 的新硬件
最近的作品,如Groq4已经展示了为LLM构建特定硬件(例如LPU)的有希望的结果和巨大潜力。 更进一步,鉴于BitNet中启用的新计算范式,我们设想并呼吁采取行动来设计专门针对1位LLM优化的新硬件和系统[23].
引用
- BZB+ [19]↑Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi.PIQA: reasoning about physical commonsense in natural language.CoRR, abs/1911.11641, 2019.
- CCKS [23]↑Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa.QuIP: 2-bit quantization of large language models with guarantees.CoRR, abs/2307.13304, 2023.
- CLC+ [19]↑Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova.Boolq: Exploring the surprising difficulty of natural yes/no questions.CoRR, abs/1905.10044, 2019.
- Com [23]↑Together Computer.Redpajama: an open dataset for training large language models, 2023.
- FAHA [23]↑Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh.OPTQ: accurate quantization for generative pre-trained transformers.In The Eleventh International Conference on Learning Representations, 2023.
- HCB+ [19]↑Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Xu Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen.Gpipe: Efficient training of giant neural networks using pipeline parallelism.In Advances in Neural Information Processing Systems, pages 103–112, 2019.
- Hor [14]↑Mark Horowitz.1.1 computing’s energy problem (and what we can do about it).In 2014 IEEE International Conference on Solid-State Circuits Conference, ISSCC 2014, Digest of Technical Papers, San Francisco, CA, USA, February 9-13, 2014, pages 10–14, 2014.
- KLZ+ [23]↑Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica.Efficient memory management for large language model serving with pagedattention.In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- LTT+ [23]↑Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han.AWQ: activation-aware weight quantization for LLM compression and acceleration.CoRR, abs/2306.00978, 2023.
- MCKS [18]↑Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal.Can a suit of armor conduct electricity? A new dataset for open book question answering.CoRR, abs/1809.02789, 2018.
- MXBS [16]↑Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher.Pointer sentinel mixture models, 2016.
- PKL+ [16]↑Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández.The LAMBADA dataset: Word prediction requiring a broad discourse context.In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Papers. The Association for Computer Linguistics, 2016.
- RSR+ [19]↑Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.Exploring the limits of transfer learning with a unified text-to-text transformer.CoRR, abs/1910.10683, 2019.
- SAL+ [24]↑Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu.Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024.
- SBBC [20]↑Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi.WinoGrande: an adversarial winograd schema challenge at scale.In The Thirty-Fourth AAAI Conference on Artificial Intelligence, pages 8732–8740, 2020.
- Sha [20]↑Noam Shazeer.GLU variants improve transformer.CoRR, abs/2002.05202, 2020.
- [17]↑Jonathan Tow, Marco Bellagente, Dakota Mahan, and Carlos Riquelme.Stablelm 3b 4e1t.
- TCS+ [24]↑Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa.Quip#: Even better LLM quantization with hadamard incoherence and lattice codebooks.CoRR, abs/2402.04396, 2024.
- TLI+ [23]↑Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample.LLaMA: open and efficient foundation language models.CoRR, abs/2302.13971, 2023.
- TMS+ [23]↑Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, and et al.Llama 2: open foundation and fine-tuned chat models.CoRR, abs/2307.09288, 2023.
- WLG [17]↑Johannes Welbl, Nelson F. Liu, and Matt Gardner.Crowdsourcing multiple choice science questions.In Leon Derczynski, Wei Xu, Alan Ritter, and Tim Baldwin, editors, Proceedings of the 3rd Workshop on Noisy User-generated Text, NUT@EMNLP 2017, Copenhagen, Denmark, September 7, 2017, pages 94–106. Association for Computational Linguistics, 2017.
- WMC+ [23]↑Lei Wang, Lingxiao Ma, Shijie Cao, Ningxin Zheng, Quanlu Zhang, Jilong Xue, Ziming Miao, Ting Cao, , and Yuqing Yang.Ladder: Efficient tensor compilation on customized data format.In OSDI, 2023.
- WMD+ [23]↑Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei.Bitnet: Scaling 1-bit transformers for large language models.CoRR, abs/2310.11453, 2023.
- XLS+ [23]↑Guangxuan Xiao, Ji Lin, Mickaël Seznec, Hao Wu, Julien Demouth, and Song Han.SmoothQuant: accurate and efficient post-training quantization for large language models.In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, 2023.
- YBS [19]↑Vikas Yadav, Steven Bethard, and Mihai Surdeanu.Quick and (not so) dirty: Unsupervised selection of justification sentences for multi-hop question answering.In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, EMNLP-IJCNLP, 2019.
- ZHB+ [19]↑Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi.HellaSwag: can a machine really finish your sentence?In Proceedings of the 57th Conference of the Association for Computational Linguistics, pages 4791–4800, 2019.
- ZS [19]↑Biao Zhang and Rico Sennrich.Root mean square layer normalization.In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems, pages 12360–12371, 2019.
- ZZL [22]↑Yichi Zhang, Zhiru Zhang, and Lukasz Lew.PokeBNN: A binary pursuit of lightweight accuracy.In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12465–12475. IEEE, 2022.
原文连接:The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (arxiv.org)