本教程演练一个简单的示例:对网站(在此示例中为 OpenAI 网站)进行爬网,使用嵌入 API 将已爬网的页面转换为嵌入,然后创建允许用户询问有关嵌入信息的问题的基本搜索功能。这旨在成为使用自定义知识库的更复杂的应用程序的起点。
原文链接:Web Q&A – OpenAI API
开始
Python 和 GitHub 的一些基本知识对本教程很有帮助。在深入研究之前,请确保设置 OpenAI API 密钥并演练快速入门教程。这将为如何充分发挥 API 的潜力提供良好的直觉。
Python与OpenAI,Pandas,transformers,NumPy和其他流行的软件包一起被用作主要的编程语言。如果您在完成本教程时遇到任何问题,请在 OpenAI 社区论坛上提问。
若要从代码开始,请在 GitHub 上克隆本教程的完整代码。或者,按照操作并将每个部分复制到 Jupyter 笔记本中,并逐步运行代码,或者只是继续阅读。避免任何问题的一个好方法是设置新的虚拟环境并通过运行以下命令安装所需的包:
|
1 2 3 4 5 |
python -m venv env source env/bin/activate pip install -r requirements.txt |
设置网络爬虫
本教程的主要重点是 OpenAI API,因此如果您愿意,可以跳过有关如何创建网络爬虫的上下文,只需下载源代码。否则,请展开以下部分以完成抓取机制的实现。
了解如何构建网络爬虫
构建嵌入索引
CSV 是存储嵌入的常用格式。您可以通过将原始文本文件(位于文本目录中)转换为 Pandas 数据框来在 Python 中使用这种格式。Pandas 是一个流行的开源库,可帮助您处理表格数据(存储在行和列中的数据)。
空白的空行可能会使文本文件混乱,并使其更难处理。一个简单的函数可以删除这些行并整理文件。
|
1 2 3 4 5 6 |
def remove_newlines(serie): serie = serie.str.replace('\n', ' ') serie = serie.str.replace('\\n', ' ') serie = serie.str.replace(' ', ' ') serie = serie.str.replace(' ', ' ') return serie |
将文本转换为 CSV 需要循环访问之前创建的文本目录中的文本文件。打开每个文件后,删除多余的间距并将修改后的文本追加到列表中。然后,将删除新行的文本添加到空的 Pandas 数据框中,并将数据框写入 CSV 文件。
额外的间距和新行会使文本混乱并使嵌入过程复杂化。此处使用的代码有助于删除其中一些,但您可能会发现 3rd 方库或其他方法可用于删除更多不必要的字符。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import pandas as pd # Create a list to store the text files texts=[] # Get all the text files in the text directory for file in os.listdir("text/" + domain + "/"): # Open the file and read the text with open("text/" + domain + "/" + file, "r", encoding="UTF-8") as f: text = f.read() # Omit the first 11 lines and the last 4 lines, then replace -, _, and #update with spaces. texts.append((file[11:-4].replace('-',' ').replace('_', ' ').replace('#update',''), text)) # Create a dataframe from the list of texts df = pd.DataFrame(texts, columns = ['fname', 'text']) # Set the text column to be the raw text with the newlines removed df['text'] = df.fname + ". " + remove_newlines(df.text) df.to_csv('processed/scraped.csv') df.head() |
标记化是将原始文本保存到 CSV 文件后的下一步。此过程通过分解句子和单词将输入文本拆分为标记。可以通过查看文档中的 Tokenizer 来查看对此的视觉演示。
一个有用的经验法则是,对于常见的英语文本,一个标记通常对应于 ~4 个字符的文本。这相当于大约一个单词的 100/75(所以 <> 个标记 ~= <> 个单词)。
API 对嵌入的最大输入令牌数有限制。为了保持在限制以下,CSV 文件中的文本需要分解为多行。将首先记录每行的现有长度,以确定需要拆分哪些行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import tiktoken # Load the cl100k_base tokenizer which is designed to work with the ada-002 model tokenizer = tiktoken.get_encoding("cl100k_base") df = pd.read_csv('processed/scraped.csv', index_col=0) df.columns = ['title', 'text'] # Tokenize the text and save the number of tokens to a new column df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x))) # Visualize the distribution of the number of tokens per row using a histogram df.n_tokens.hist() |
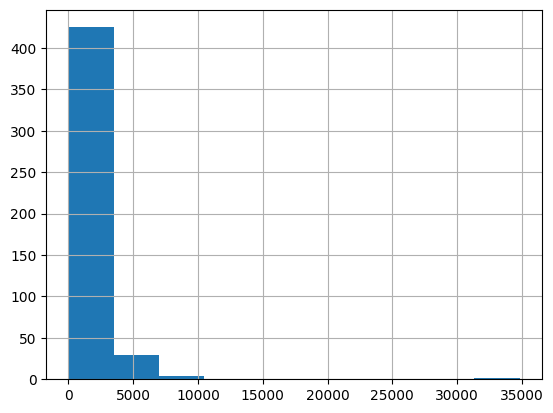
最新的嵌入模型可以处理最多 8191 个输入标记的输入,因此大多数行不需要任何分块,但可能不是每个抓取的子页面的情况,因此下一个代码块会将较长的行拆分为较小的块。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
max_tokens = 500 # Function to split the text into chunks of a maximum number of tokens def split_into_many(text, max_tokens = max_tokens): # Split the text into sentences sentences = text.split('. ') # Get the number of tokens for each sentence n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences] chunks = [] tokens_so_far = 0 chunk = [] # Loop through the sentences and tokens joined together in a tuple for sentence, token in zip(sentences, n_tokens): # If the number of tokens so far plus the number of tokens in the current sentence is greater # than the max number of tokens, then add the chunk to the list of chunks and reset # the chunk and tokens so far if tokens_so_far + token > max_tokens: chunks.append(". ".join(chunk) + ".") chunk = [] tokens_so_far = 0 # If the number of tokens in the current sentence is greater than the max number of # tokens, go to the next sentence if token > max_tokens: continue # Otherwise, add the sentence to the chunk and add the number of tokens to the total chunk.append(sentence) tokens_so_far += token + 1 return chunks shortened = [] # Loop through the dataframe for row in df.iterrows(): # If the text is None, go to the next row if row[1]['text'] is None: continue # If the number of tokens is greater than the max number of tokens, split the text into chunks if row[1]['n_tokens'] > max_tokens: shortened += split_into_many(row[1]['text']) # Otherwise, add the text to the list of shortened texts else: shortened.append( row[1]['text'] ) |
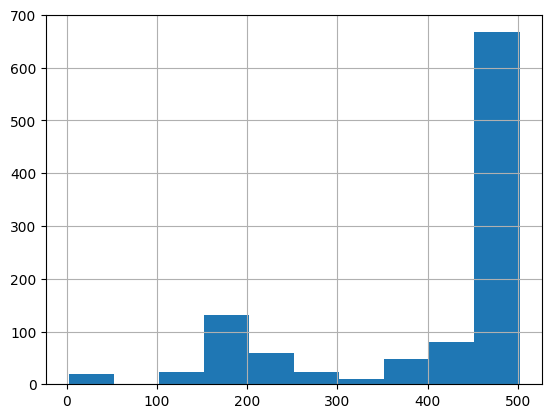
再次可视化更新的直方图有助于确认行是否已成功拆分为缩短的部分。
|
1 2 3 |
df = pd.DataFrame(shortened, columns = ['text']) df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x))) df.n_tokens.hist() |
内容现在被分解为更小的块,并且可以向 OpenAI API 发送一个简单的请求,指定使用新的文本嵌入 ada-002 模型来创建嵌入:
|
1 2 3 4 5 6 |
import openai df['embeddings'] = df.text.apply(lambda x: openai.Embedding.create(input=x, engine='text-embedding-ada-002')['data'][0]['embedding']) df.to_csv('processed/embeddings.csv') df.head() |
这应该需要大约 3-5 分钟,但之后您将准备好使用您的嵌入!
使用嵌入构建问答系统
嵌入已准备就绪,此过程的最后一步是创建一个简单的问答系统。这将接受用户的问题,创建它的嵌入,并将其与现有嵌入进行比较,以从抓取的网站中检索最相关的文本。然后,text-davinci-003 模型将根据检索到的文本生成一个自然听起来不错的答案。
将嵌入转换为 NumPy 数组是第一步,鉴于在 NumPy 数组上运行的许多可用函数,这将为如何使用它提供更大的灵活性。它还会将维度展平为 1-D,这是许多后续操作所需的格式。
|
1 2 3 4 5 6 7 |
import numpy as np from openai.embeddings_utils import distances_from_embeddings df=pd.read_csv('processed/embeddings.csv', index_col=0) df['embeddings'] = df['embeddings'].apply(eval).apply(np.array) df.head() |
现在数据已准备就绪,该问题需要转换为具有简单函数的嵌入。这很重要,因为使用嵌入的搜索使用余弦距离比较数字向量(这是原始文本的转换)。向量可能是相关的,如果它们的余弦距离接近,则可能是问题的答案。OpenAI python包有一个内置函数,在这里很有用。distances_from_embeddings
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
def create_context( question, df, max_len=1800, size="ada" ): """ Create a context for a question by finding the most similar context from the dataframe """ # Get the embeddings for the question q_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding'] # Get the distances from the embeddings df['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine') returns = [] cur_len = 0 # Sort by distance and add the text to the context until the context is too long for i, row in df.sort_values('distances', ascending=True).iterrows(): # Add the length of the text to the current length cur_len += row['n_tokens'] + 4 # If the context is too long, break if cur_len > max_len: break # Else add it to the text that is being returned returns.append(row["text"]) # Return the context return "\n\n###\n\n".join(returns) |
文本被分解为较小的标记集,因此按升序循环并继续添加文本是确保完整答案的关键步骤。如果返回的内容多于所需内容,也可以将max_len修改为较小的内容。
上一步仅检索与问题语义相关的文本块,因此它们可能包含答案,但无法保证。通过返回前 5 个最可能的结果,可以进一步增加找到答案的机会。
然后,回答提示将尝试从检索到的上下文中提取相关事实,以便制定连贯的答案。如果没有相关答案,提示将返回“我不知道”。
可以使用完成端点创建问题的现实答案。text-davinci-003
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
def answer_question( df, model="text-davinci-003", question="Am I allowed to publish model outputs to Twitter, without a human review?", max_len=1800, size="ada", debug=False, max_tokens=150, stop_sequence=None ): """ Answer a question based on the most similar context from the dataframe texts """ context = create_context( question, df, max_len=max_len, size=size, ) # If debug, print the raw model response if debug: print("Context:\n" + context) print("\n\n") try: # Create a completions using the question and context response = openai.Completion.create( prompt=f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:", temperature=0, max_tokens=max_tokens, top_p=1, frequency_penalty=0, presence_penalty=0, stop=stop_sequence, model=model, ) return response["choices"][0]["text"].strip() except Exception as e: print(e) return "" |
大功告成!一个从OpenAI网站嵌入知识的工作问答系统现在已经准备好了。可以进行一些快速测试以查看输出的质量:
|
1 2 3 4 5 |
answer_question(df, question="What day is it?", debug=False) answer_question(df, question="What is our newest embeddings model?") answer_question(df, question="What is ChatGPT?") |
响应将如下所示:
|
1 2 3 4 5 |
"I don't know." 'The newest embeddings model is text-embedding-ada-002.' 'ChatGPT is a model trained to interact in a conversational way. It is able to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.' |
如果系统无法回答预期的问题,则值得搜索原始文本文件,以查看预期已知的信息是否实际上最终被嵌入。最初完成的爬网过程设置为跳过提供的原始网域之外的网站,因此如果有子网域设置,它可能没有该知识。
目前,每次都会传入数据帧以回答问题。对于更多的生产工作流程,应使用矢量数据库解决方案,而不是将嵌入存储在CSV文件中,但当前的方法是一个很好的原型设计选择。